文章目录
- 前言
- 摘要
- 一、介绍
- 二、相关工作
- 2.1步态识别
- 2.2端到端学习
- 三、跨域问题
- 四、我们的框架
- 4.1步法合成
- 4.2步态对准模块
- 五、实验
- 5.1设置
- 5.2性能比较
- 5.3消融实验
- 5.4可视化
- 六、结论
前言
本篇博客仅为个人学习,全文均为知云翻译,如有翻译不当,欢迎指出
摘要

步态是一种最有前途的远距离个体识别方法。虽然大多数先前的方法都集中在识别轮廓上,但是一些直接从RGB图像中提取步态特征的端到端方法表现得更好。然而,我们证明了这些端到端方法不可避免地会受到与步态无关的噪声的影响,即低层次纹理和彩色信息。
实验上,我们设计了跨域评估来支持这一观点。在这项工作中,我们提出了一种新的端到端框架GaitEdge,它可以有效地阻断步态无关信息,释放端到端的训练潜力。具体来说,GaitEdge合成行人分割网络的输出,然后将其馈送到后续的识别网络,其中合成的轮廓由可训练的身体边缘和固定的内部组成,以限制识别网络接收的信息。此外,将用于对齐轮廓的GaitAlign嵌入到GaitEdge中,而不会失去可微分性。在CASIA-B和我们新构建的TTG-200上的实验结果表明,GaitEdge显著优于以前的方法,并提供了更实用的端到端范式。所有的源代码都可以在https://github.com/ShiqiYu/OpenGait上获得。
一、介绍
近年来,基于行走模式即步态的人类身份识别已成为一个研究热点。与人脸、指纹、虹膜等其他生物特征相比,人体步态可以在不需要受试者配合的情况下轻松远距离捕获,这意味着步态在现实世界非受控条件下可以用于犯罪调查和嫌疑人追踪。需要注意的是,大多数研究都将步态识别作为一个两步的方法,包括从RGB图像中提取中间模态,如轮廓掩模或骨架关键点,并将其放入下游步态识别网络中。
然而,一些研究[4,5,7,16]表明,多步骤管道通常会导致效率和有效性的弱点;越来越多的研究倾向于直接推断端到端的最终结果[30,20,14]。
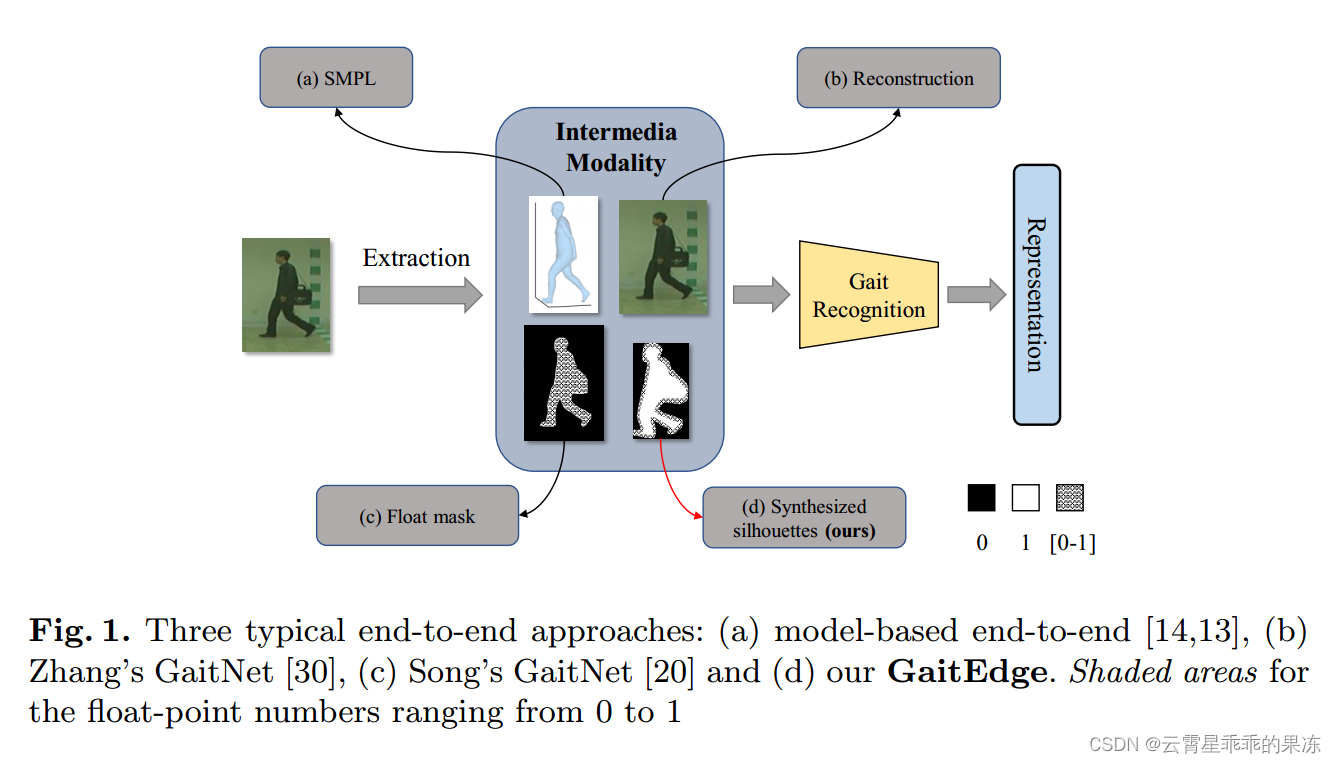
据我们所知,在最近的文献中,有三种典型的端到端步态识别方法。如图1 (a)所示,Li等人[14,13]利用时尚人体网格恢复模型[11]重建三维人体,并以蒙皮多人线性(SMPL)[17]模型的参数作为输入训练识别网络。
Zhang等人[30]提出的另一种典型方法是引入自编码器框架,从顺序RGB图像中明确分离出与运动相关的步态模式和与运动无关的外观特征,如图1 (b)所示。此外,Song等人提出了GaitNet[20],该方法集成了行人分割和步态识别两项任务。如图1 ©所示。它直接从中间浮动掩模中提取步态特征,而不是从经典的二元轮廓中提取。
尽管取得了比两步方法更高的性能,但我们认为这些端到端方法不能确保人类识别的学习特征仅由行走模式组成。由于之前的端到端框架的中间模式,如[14,13]中的SMPL重建、[30]中的姿态特征解纠缠和[20]中的行人分割监督,都是浮点编码,它们可能会引入一些背景和纹理信息。此外,虽然以前的方法都试图排除步态无关的特征,但它们缺乏令人信服的实验来验证。
为了缓解这些问题,我们注意到步态特征对于摄像机视点、携带和服装的协变通常比其他与步态无关的噪声(即纹理和颜色)更具鲁棒性,这意味着如果这些不相关的特征在提取的步态表示中占主导地位,那么当模型直接在未见域(新数据集)中利用时,识别性能将下降很多[8]。因此,在本文中,我们引入了跨域评估来暴露RGB信息的副作用。更重要的是,我们提出了一个简洁而引人注目的端到端框架GaitEdge来处理这个具有挑战性的评估。如图1 (d)所示,GaitEdge的中间模态是一个新的合成轮廓,其边缘由可训练的浮动掩模组成,其他区域为经典的二元轮廓。
两个直观的现象启发了这个设计:首先,rgb通知噪声主要分布在非边缘区域,如人体和背景。因此,将这些区域处理为二元轮廓可以有效地防止步态无关噪声的泄漏。其次,边缘区域在描述人体形状方面起着至关重要的作用。因此,使唯一的边缘区域可训练就足以释放端到端训练策略的潜力。此外,我们观察到尺寸归一化对齐[9]对于轮廓预处理是必要的,以保持身体的长宽比。不幸的是,这个操作过去是离线的,因此不可微分,这意味着它不能直接应用于对齐合成轮廓。为了解决这个问题,受RoIAlign[6]的启发,我们提出了GaitAlign模块来完成GaitEdge的框架,这可以看作是[9]提出的对齐方法的可微版本。
综上所述,我们做出了以下三个主要贡献:(1)我们指出了对步态无关噪声混入最终步态表示的担忧,并引入了跨域测试来验证rgb通知噪声的泄漏。此外,由于缺乏提供RGB视频的步态数据集,我们收集了10000 Gaits (TTG-200),其大小与流行的CASIA-B大致相等[26]。(2)我们提出了GaitEdge,一个简洁而引人注目的端到端步态识别框架。在CASIA-B和TTG-200上的实验表明,GaitEdge达到了新的最先进的性能,并且我们宣布GaitEdge可以有效地防止无关的RGBinformed噪声。(3)我们提出了一个基于轮廓的端到端步态识别模块GaitAlign,它可以被认为是尺寸归一化的可微分版本[9]。
 图片下文字的翻译:
图片下文字的翻译:
三种典型的端到端方法:(a)基于模型的端到端[14,13],(b) Zhang的GaitNet [30], © Song的GaitNet[20]和(d)我们的GaitEdge。阴影区域表示从0到1的浮点数
二、相关工作
2.1步态识别
步态作为一种生物特征识别,早期的研究将其定义为[23],即给定的人以一种具有一定重复性和特征性的方式进行的行走方式。另一方面,另一个类似的任务,即人的再识别[31],目的是在另一个相机的另一个地方找到一个在一个相机中出现的人。尽管有相似之处,但它们仍有本质上的不同:第一个任务侧重于行走模式,而第二个任务主要使用衣服来识别。因此,值得强调的是,我们不能让步态识别网络获取步态模式以外的信息,如rgb通知的纹理和颜色。
目前主流的基于视觉的步态识别方法大致可以分为基于模型的和基于外观的。以往基于模型的方法[15,2,14,22]通常先提取人体底层结构,如二维或三维骨架关键点,然后对人体行走模式进行建模。一般来说,这种方法可以更好地减轻衣服的影响,更准确地描述身体的姿势。但是,由于视频质量不高,这些方法都难以在实际监控场景下对人体结构进行建模。
目前越来越多的基于外观的步态识别方法[24,28,4,29,5,7,16]将基于模型的方法抛在了后面。最近,GaitSet[4]将一系列轮廓作为输入,取得了很大的进展。随后,Fan等[5]提出了一个焦点卷积层来学习局部级特征,并利用Micro-motion Capture Module来建模短期时间模式。
此外,Lin等[16]提出了一种基于3D cnn的Global and Local Feature Extractor模块,用于从帧中提取判别性的全局和局部表征,显著优于其他方法。
2.2端到端学习
端到端学习是指将多个独立的基于梯度的深度学习模块以可微的方式进行集成。这种训练模式具有天然的优势,因为系统优化组件的整体性能,而不是优化人为选择的中间部分[3]。
最近,一些优秀的研究得益于端到端学习范式。Amodei等人[1]用神经网络取代了手工设计组件的整个管道,通过端到端学习克服了语音的多样性。另一个值得注意的工作[3]是Nvidia针对自动驾驶系统的端到端训练。它只给系统提供人的转向角度作为训练信号。尽管如此,系统仍然可以自动学习必要处理步骤的内部表示,例如检测车道线。
随着端到端理念变得越来越流行,一些研究[30,14,20]将其应用于步态识别。首先,Zhang等人[30]提出了一种自动编码器,在没有明确的外观和步态标签的情况下,将外观和步态信息分开进行监督。其次,Li等人[14,13]使用新开发的三维人体网格模型[17]作为中间模态,使神经网络三维网格渲染器[12]生成的轮廓与RGB图像分割的轮廓一致。因为3D网格模型提供了比轮廓更有用的信息,这种方法达到了最先进的结果。然而,使用3D网格模型需要更高分辨率的输入RGB图像,这在实际监控场景中是不可行的。与前两种不同的是,Song等[20]提出了另一种端到端步态识别框架。它由行人分割和步态识别网络直接连接而成,并由分割损失和识别损失共同监督。这种方法看起来相对更适用,但由于缺乏明确的限制,它也可能导致与步态无关的噪声泄漏到识别网络中。
在这种考虑下,我们的GaitEdge主要提出并解决了两个关键问题:跨域评估和轮廓错位。
三、跨域问题
从之前的角度来看,我们认为虽然现有的端到端方法[30,20,14,13]大大提高了准确率,但人们很自然地怀疑RGB信息的引入是提高准确率的原因。为了验证我们的猜想,我们引入了两种步态识别范式并进行了实验比较。
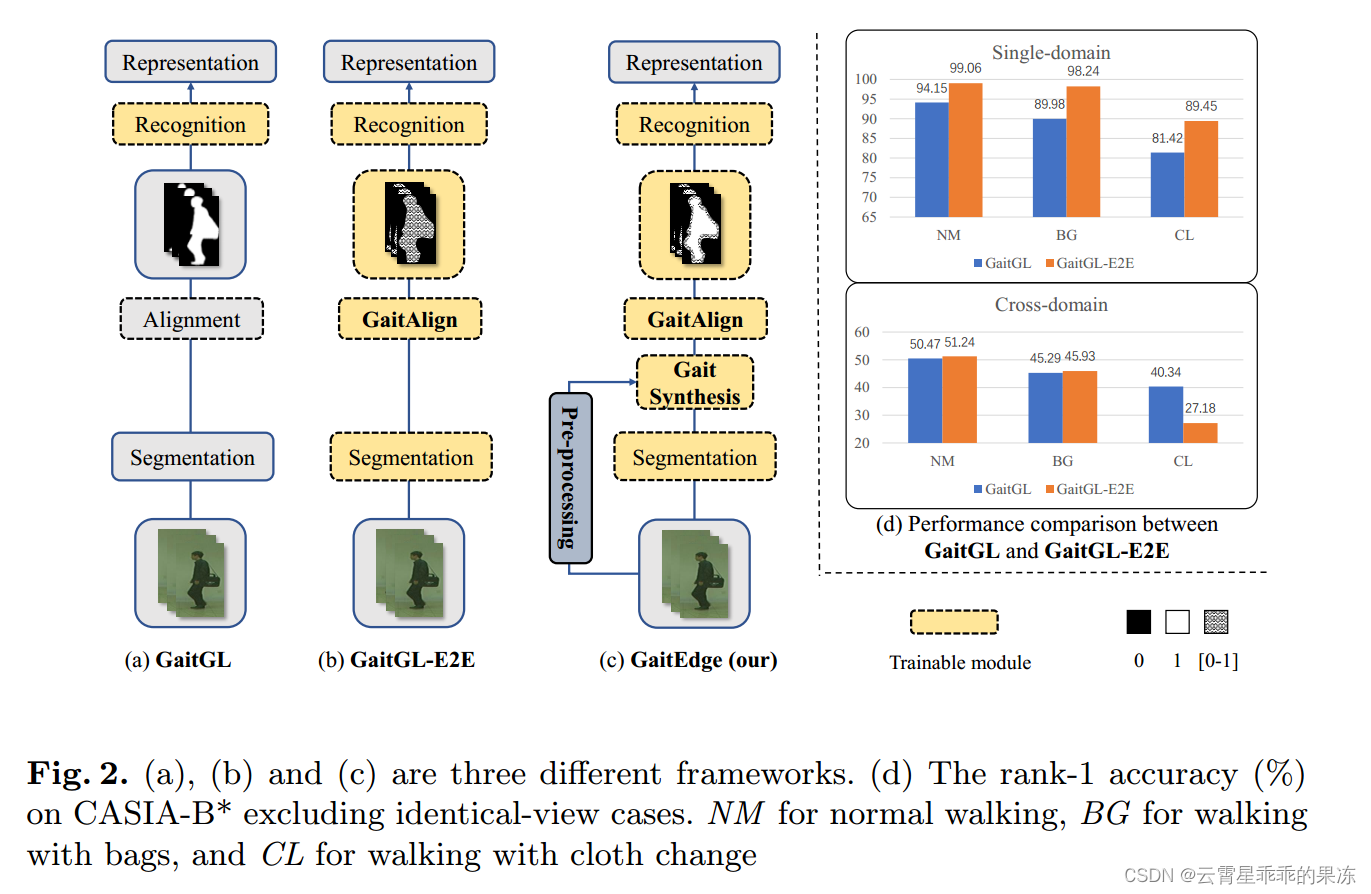
首先,采用目前性能最好的两步步态识别方法之一GaitGL[16]作为基线。此外,还介绍了一个简单直接的端到端模型GaitGL-E2E,该模型提供了公平的比较。如图2 (a)和(b)所示,两种方法使用的模块相同,只是GaitGL-E2E通过可训练的分割网络,即U-Net,将二进制掩码替换为浮点编码轮廓[18]。在实验上,我们将单域评价定义为CASIA-B*5上的训练和测试[26]。
相应地,跨域评估定义为在另一个数据集TTG-200上进行训练,但在CASIA-B*上对训练好的模型进行测试。更多的实现细节将在第5节中详细阐述。
如图2 (d)的单域部分所示,由于GaitGL- e2e具有更多的可训练参数,并且浮点掩码比二进制掩码包含更多的信息,因此GaitGL- e2e轻松优于GaitGL。然而,人们不可避免地会怀疑,流入识别网络的浮点数带来了RGB图像的纹理和颜色,这会使识别网络学习与步态无关的信息,从而导致跨域性能的下降。另一方面,从图2 (d)的跨域部分可以看出,在最具挑战性的情况下,即CL (walking with cloth change), GaitGL- e2e并没有达到单域的优势,甚至远低于GaitGL (GaitGL: 40.34%, GaitGLE2E: 27.18%)。
这一现象表明,端到端模型更容易学习容易识别的粗粒度RGB信息,而不是细粒度难以察觉的步态模式。
以上两个实验表明,GaitGL-E2E确实会吸收RGB噪声,对于具有实际跨域要求的步态识别不再可靠。因此,我们提出了一个由我们精心设计的步态合成模块和可微的GaitAlign模块组成的新框架GaitEdge,如图2 ©所示。GaitEdge与GaitGL-E2E最显著的区别在于我们通过人工轮廓合成来控制RGB信息的传输。
图片下文字的翻译:
图2所示。(a)、(b)和©是三个不同的框架。(d) CASIA-B*上排除同视图病例的rank-1准确度(%)。NM为正常行走,BG为带袋行走,CL为带换布行走
四、我们的框架
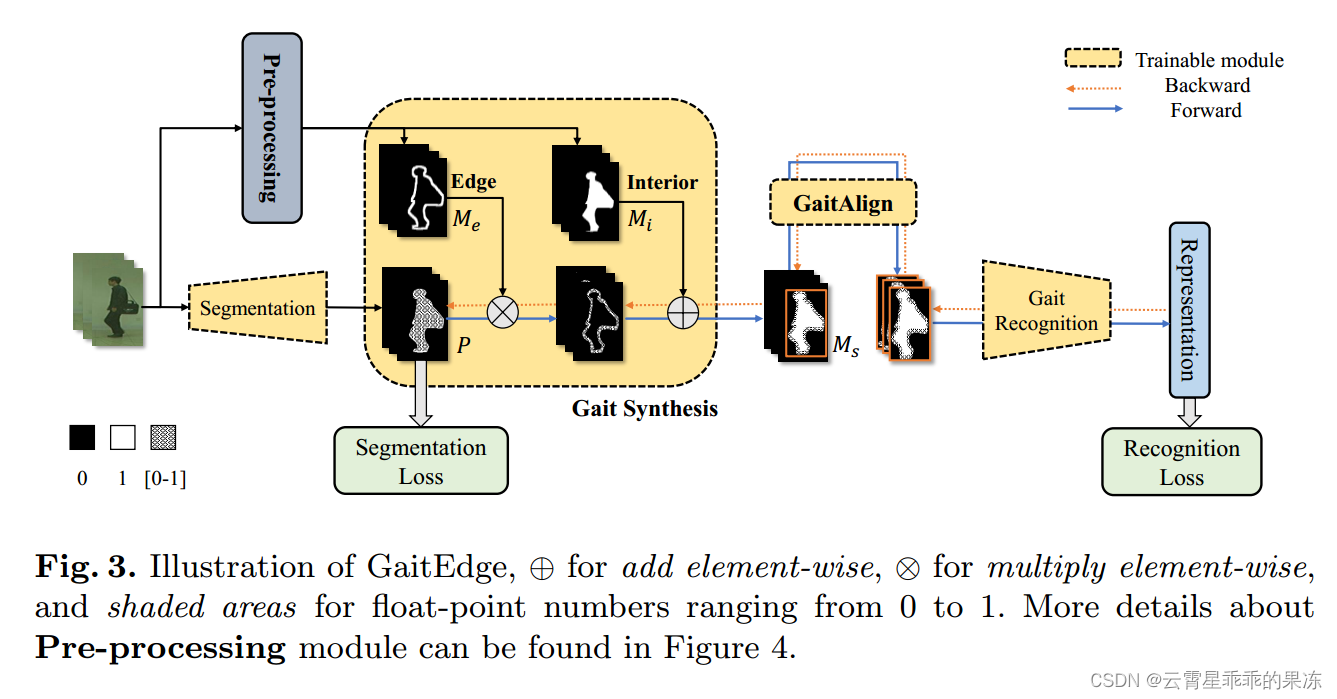 图3所示。GaitEdge的图解,⊕表示加法元素,⊗表示乘法元素,阴影区域表示从0到1的浮点数。关于预处理模块的更多细节见图4。
图3所示。GaitEdge的图解,⊕表示加法元素,⊗表示乘法元素,阴影区域表示从0到1的浮点数。关于预处理模块的更多细节见图4。
4.1步法合成
我们一般认为,轮廓图像中,边缘(轮廓的轮廓)包含了最具判别性的信息[25]。剪影内部可以看作是信息较少的低频内容,但是如果去掉剪影内部,信息过于紧凑,无法训练识别网络。因此,设计的模块命名为步态合成,重点是通过掩模操作将可训练的边缘与固定的内部结合起来。它只训练轮廓图像的边缘部分,从冻结分割网络中提取边缘以外的区域。如图3所示,为了阐明我们的框架是如何工作的,我们使用黄色表示可训练模块,并说明梯度传输的流程,其中橙色虚线表示向后传播,蓝色实线表示向前传播。边缘和内部的掩模分别表示为Me和Mi。
将分割网络的输出概率记为p。然后,步态合成的输出记为Ms,可以通过几个元素运算得到:

如公式1所示,我们显式地将Ps乘以Me,然后将其加到Mi上,这将屏蔽大部分信息,包括步态相关和步态无关的信息。
然而,我们仍然可以微调轮廓的边缘,使其自动优化识别。
预处理。我们设计了一个不可训练的预处理操作来获取Me和Mi,如图4所示。具体来说,我们将其分为三个步骤。首先,我们使用训练好的分割模型对输入的RGB图像进行分割,得到轮廓m。第二步,我们使用经典的形态学算法得到具有3 × 3平面结构元素的扩张和侵蚀轮廓(Mi)。最后,我们通过元素独占或⊻获得Me。正式:

总体而言,步态合成采用最直观的方法,通过限制可调区域来保留最有价值的轮廓特征,同时消除大多数低水平rgb通知噪声。值得一提的是,由于设计简单,步态合成可以与先前基于轮廓的端到端方法可拆卸集成。
4.2步态对准模块


在所有基于轮廓的步态识别方法中,定位是至关重要的。由于轮廓的尺寸归一化是首次在OUISIR步态数据库中使用[9],几乎所有基于轮廓的方法都是通过尺寸归一化对轮廓输入进行预处理,这样可以去除噪声,有利于识别。然而,之前的端到端方法,即GaitNet[20],将分割后的轮廓直接输入到识别网络中,很难处理上述情况。因此,我们提出了一种可微分的步态对齐模块GaitAlign,使人体成为图像的中心,垂直填充整个图像。
我们首先回顾大小归一化[9]过程,因为GaitAlign可以被视为一个可微版本。在尺寸归一化中,通过计算出主体的顶部、底部和水平中心,我们可以将主体按长宽比缩放到目标高度,然后在x轴上填充零以达到目标宽度。在我们的例子中,算法1中的伪代码描述了GaitAlign的过程。我们首先需要用零宽度的一半填充左右两边,以确保裁剪操作不会超出边界。然后根据纵横比和目标尺寸计算出四个规则采样位置的精确值。最后,将RoIAlign[6]应用于上一步给出的位置。因此,我们得到了标准尺寸的、图像填充的轮廓,其长宽比保持不变(参见图3中的GaitAlign输出)。另一个值得注意的一点是,GaitAlign模块仍然是可微的,这使得我们的端到端训练是可行的。
五、实验

5.1设置
数据集。 步态识别有一些可用的数据集,如CASIAB[26]、OUMVLP[21]、outdoor -步态[20]、FVG[30]、GREW[32]等。
然而,并不是所有的方法都适用于端到端步态识别方法。例如,本文不能应用世界上最庞大的两个步态数据集OUMVLP[21]和GREW[32],因为它们都没有提供RGB视频。简而言之,我们理想的步态数据集拥有几个重要属性:可用的RGB视频、丰富的摄像机视点和多种行走条件。
CASIA-B[26]似乎是一个不错的选择。然而,仍然需要另一个类似的数据集来适应我们的跨域设置。因此,我们收集了一个名为10000 Gaits 200 (TTG-200)的私有数据集,并在表1中显示了它的统计信息。
CASIA-B。 CASIA-B有124名受试者在室内行走。它可能是最流行的数据集,由11个视图([0◦-180◦])和三种行走条件组成,即正常行走(NM#01-06),带袋行走(BG#01-02)和带布料行走(CL#01-02)。我们严格遵循先前的研究,将前74名受试者分为训练集,其他受试者分为测试集。
进一步,在测试阶段,将前4个序列(NM#01-04)作为画廊集,其余6个序列分为3个探针子集,即NM#05-06, BG#01-02, CL#01-02。此外,由于CASIA-B的剪影是通过过时的背景减法获得的,因此由于拍摄对象的背景和衣服等因素,存在很大的噪声。因此,我们将CASIA-B的剪影重新标注为CASIA-B*。我们所有的实验都是在这个新标注的上面进行的。

ttg - 200。 这个数据集包含200个在野外行走的受试者,每个人
受试者需要在6种不同的条件下行走,即负重,穿着,
接电话,等等。对于每个行走过程,受试者将
由位于不同视点周围的12台摄像机捕获(未标记),这意味着每个受试者理想地拥有6 × 12 = 72个步态序列。在接下来的实验中,我们将前120名受试者进行训练,后80名受试者进行测试。另外,将第一个序列(#1)视为廊集,将剩下的5个序列(#2-6)视为探测集。
如图5所示,与CASIA-B相比,TTG-200主要有三个不同之处:(1)TTG-200的背景更加复杂多样(采集于多个不同的户外场景);(2) TTG-200数据多为鸟瞰图,CASIA-B数据多为水平视图;(3) TTG200具有更好的图像质量。因此,我们可以将这两个数据集视为不同的域。
实现细节
数据预处理。我们首先使用ByteTrack[27]从CASIA-B[26]和TTG-200的原始RGB视频中检测和跟踪行人,然后进行人体分割和轮廓对齐[9]提取步态序列。得到的轮廓被调整为64 × 44,可以作为两阶段步态识别方法的输入,也可以作为这些端到端方法中行人分割网络的ground-truth。
行人分割。我们使用流行的U-Net[18]作为我们的分割网络,该网络由二元交叉熵[10]损失Lseg监督。我们设置输入大小为128 × 128 × 3, U-Net通道为{3,16,32,64,128,64,32,16,1},并通过SGD进行训练[19](批大小=960,动量=0.9,初始学习率=0.1,权值衰减=5 × 10−4)。对于每个数据集,我们以学习率缩放到1/10的速度训练网络,每10000次迭代两次,直到收敛。
步态识别。我们使用最新的GaitGL[16]作为我们的识别网络,并严格遵循原论文的设置。
联合训练细节。在这一步中,训练数据的采样器和批处理大小与步态识别网络相似。我们用联合损失Ljoint = λLseg + Lrec对分割和识别网络进行联合微调,其中Lrec表示识别网络的损失。λ表示分割网络的损失权值,设为10。此外,为了使联合训练过程收敛得更快,我们使用训练好的分割和识别网络参数初始化端到端模型,初始学习率分别设置为10−5和10−4。并且,我们固定了分割网络的前半部分,即U-Net,使分割结果保持人形。我们共同训练端到端网络共20000次迭代,在第10000次迭代时学习率降低了1/10。

5.2性能比较
为了证明GaitEdge具有可靠的跨域能力,我们对CASIA-B*和TTG-200进行了单域和跨域评估,如表2所示。
表2的对角线显示了单域性能比较,其中这些方法在相同的数据集中进行训练和评估。相反,反对角线显示跨域性能比较,其中这些方法在不同的数据集中进行训练和评估。
单极评价。 从表2的对角线结果可以看出,传统的两步步态识别方法的性能远远不如端到端两步步态识别方法。例如,CASIA-B的GaitGL-E2E分别超过GaitSet[4]的11.66%和TTG-200的12.75%。另一方面,我们提出的GaitEdge的准确率略低于GaitGL-E2E, CASIA-B为-2.13%,TTG-200为-1.71%。然而,我们认为GaitGL-E2E在步态无关噪声中具有较高的过拟合风险,因为它直接将分割网络产生的浮动掩码作为识别网络的输入。因此,我们进一步进行跨领域评估,以实验支持这一概念。
跨域评估。 如果一些不相关的噪声主导了用于人类识别的步态表征,即纹理和颜色,则识别效果将会降低
在跨域设置的情况下,准确性会急剧下降
提取的特征不能代表相对稳健的步态模式。的
表2的反对角结果表明,所有这些方法都具有显著的
由于CASIA-B*和TTG-200之间的显著差异,与单域相比性能下降。我们注意到,尽管GaitGL-E2E
单域精度最高,但性能最差
用于从CASIA-B*跨越域到TTG-200。相比之下,我们的GaitEdge在跨域评估中达到了最好的性能,尽管在单域评估中比GaitGL-E2E低约2%。
因此,这种跨域评估不仅表明GaitEdge的鲁棒性远远优于GaitGL-E2E,而且表明GaitEdge是一种实用的、先进的端到端步态识别框架。
与其他端到端方法的比较。 最后,在CASIA-B*上,将所提出的GaitEdge与之前三种不同视角的端到端步态识别方法进行了比较。从表3可以看出,GaitEdge在各种步行条件下的准确率几乎都是最高的,特别是对于CL(比mvmodel步态+5.7%),这表明GaitEdge对颜色和纹理(布料变化)具有非常强的鲁棒性。

5.3消融实验
边缘的影响。 表4显示了车身边缘尺寸的影响。我们通过不同大小的结构元素提取边缘,结构元素越大,边缘面积越大。从表4的结果可以看出,随着结构单元尺寸的增大,单域性能相应提高,而跨域性能几乎同时下降。该结果表明,占据中间合成轮廓的浮动掩模面积与GaitEdge的跨域性能呈负相关。因此,我们可以认为,GaitGLE2E之所以在跨域评估中失败,是因为在无限结构单元的情况下,它与GaitEdge是等价的。此外,对于端到端步态识别框架而言,轮廓的非边缘区域(即人体和背景)不适合进行浮点编码。

GaitAlign的影响。 值得注意的是,我们观察到自然场景下行人检测(上游任务)的结果往往比受控环境(即CASIA-B和TTG-200)差得多。为了模拟这种复杂的情况,我们首先对CASIA-B的视频进行目标检测,然后以0.5的概率沿垂直和水平坐标随机进行像素偏移。如图6 (a)所示,为了模拟自然情况,对底部的图像进行了扰动处理。图6 (b)显示,对准可以显著提高平均精度。此外,我们还注意到正常行走(NM)的准确率略有下降,即-0.38%。然而,我们认为这是因为NM的精度正在接近上限。

5.4可视化
为了更好地理解GaitGL-E2E的性能退化和GaitEdge的有效性,我们分别给出了GaitGLE2E和GaitEdge生成的中间结果以及对应于同一帧的ground truth,如图7所示。具体来说,对于GaitGL-E2E, (a)、(b)、©和(d)的中间结果捕获了更多的背景和纹理信息,并且消除了(e)和(f)中的一些身体部位,例如腿。而对于GaitEdge,中间结果更加稳定和合理,使其更具鲁棒性

六、结论
提出了一种新的端到端步态识别框架GaitEdge,解决了跨域情况下的性能下降问题。
具体来说,我们设计了一个步态合成模块,用形态学运算得到的可调边缘来掩盖固定的身体。此外,为了解决上游行人检测任务引起的车身位置抖动问题,提出了一种可微对齐模块GaitAlign。我们还在CASIA-B*和我们新建的TTG-200两个数据集上进行了广泛而全面的实验。实验结果表明,GaitEdge方法明显优于以往的方法,表明GaitEdge是一种更实用的端到端范式,可以有效地阻挡RGB噪声。此外,本研究还揭示了以往研究忽略的跨领域问题,为今后的研究提供了新的视角。

![K8S controller编写之Informer的原理+使用[drift]](https://img-blog.csdnimg.cn/direct/28de4fb771fb4b84bda3855ec838ea41.png)